Intelligent Load Balancing with APIM: Using Weight-Based Routing for Improved OpenAI Performance
I have been working as App/Infra Solution Architect with Microsoft from 5 years. Helping diverse set of customers across vertical i.e. BFSI, ITES, Digital Native in their journey towards cloud
Ever Since launch of ChatGPT, demand for OpenAI GPT Models has increased exponentially.
Due such vast demand in short span of time, its been challenging for customer to get thier desired capacity in thier respective region
In that case my recommendation has been to deploy multiple OpenAI instance with S0 plan(Token-based-consumption) in any region where capacity is available & then used an load Balancer as fascade to distribute traffic across all your Az OPAI endpoints
Each OpenAI Models has its own limit called token limit which is measured based per minute i.e. TPM. In this case i am referring to GPT3.5 Model which comes with maximum TPM limit of 300K for an given region
Since there is surge in demand from customer all over world for LLM models like GPT, we have limited capacity of OpenAI instance in each region.
Many Customer specially D2C eventually get requirment of over 700-800K+ token for thier use case.
In that scenario customers tend to deploy OpenAI Instance with S0 plan across multiple location
Although TPM limit for all instance is not same because of capacity constrain overall
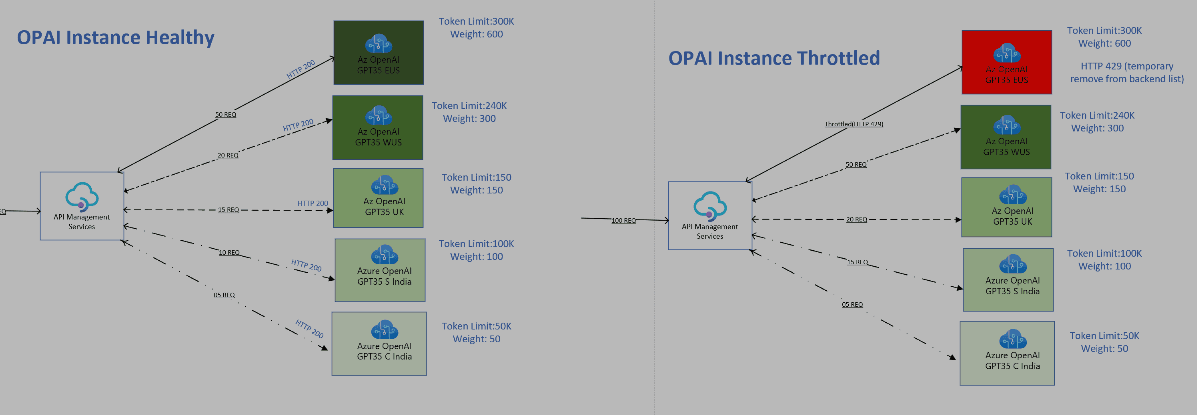
Following is real world example of customer which uses multiple OpenAI instance with different TPM limit for each region
OpenAI-EastUS :300k
OpenAI-WestUS: 240K
OpenAI-SouthUK: 150K
OpenAI-Southindia:100k
OpenAI-CentralIndia:50K
Why not use existing Load balancers & how it is different from other existing LB technique?
There are multiple load balancing option are now available using AppGW/FrontDoor or API management custom policies with algorithm based on roundrobin, random or even prirotiy based. Although there are some cons with each routing algorithm
AppGW/FrontDoor:Roundrobin pattern to Distribte traffic across OpeAI endpoints.
Can be used in scenario when all OpenAI instance has same TPM Limit.But it cannot do health probe of OpenAI endpoints if its TPM exhausted & received HTTP 429(Server is Busy) & it will continue to forward request to throttled openai endpoint
API management:
One differentiting capablities with APIM using its policies that it is aware about endpoint HTTP 429 status code and offers Retry mechanism which allows send traffic to another available endpoints from backend pool until current endpoints becomes active/healthy again.
APIM Policies for OpenAI:
Roundrobin: if you have multiple OpenAI endpoint across location in APIM backendpool, it simply select any of backend based on roundrobin provided its not being throtlled at that moment & it distribute traffic across sequentially doesnt honor OpenAI Endpoints TPM limits
Random: Its mostly similar with roundrobin method, primary differnence is that it selected backend endpoint randomly from backend pool. & its also doesnt honor openai TPM limit
Priority: In this case if you have endpoint across many location, you can assigned priotiy order sequence either based on TPM limit or latency from your base region,
But even then all traffic would always forwarded to endpoint which has lowest priority & rest of available openai endpoint would simply be waiting on standby unless lowest priority instance is throttled
Now in ths case customer requested for load balancing technique based on its TPM limit assigned against each OpenAI endpoint which should distribute traffic accordingly.
Weightage:
There is no direct feature capablities in APIM for weightage based routing.I have tried achieve same results using custom logic with APIM policies
Selection Process:
Backend logic used in this policy is based on weighted selection method to choose an endpoint route for retry.endpoint with higher weights are more likely to be chosen, but each endpoints route has at least some chance of being selected. This is because the selection is based on a random number that is compared against cumulative weights, which means the selection process inherently favors routes with higher weights due to the way cumulative weights are calculated and utilized. Let’s break down the process with a simple example to clarify how routes with higher weights are more likely to be selected.
*in this image, its deplects APIM configured based on Weight policy across OpenAI

There are three variable used in selelction process for backend
1)Totalweight
2)Cumulative weight
3)Random Number
Example: Lets understand this policy using following based on above image
Assume you have five openai endpoints as mentioned in image with following weight
Endpoint A: Weight = 50
Endpoint B: Weight = 100
Endpoint C: Weight = 150
Endpoint D: Weight = 300
Endpoint E: Weight = 600
Step 1:Calculate Total Weight
First, you calculate the total weight of all endpoint routes, which in this case would be 50+100+150+300+600=1200.
Step 2: Generate Random Weight
Next, a random number (let’s call it randomWeight) is generated between 1 and the total weight (inclusive). So, randomWeight is between 1 and 1200.
Step 3: Calculate Cumulative Weights
The cumulative weights are calculated to determine the ranges that correspond to each endpoint route. Here’s how they look based on the weights:
Cumulative Weight after Endpoint A: 50 (just the weight of A,)
Cumulative Weight after Endpoint B: 100 (the weight of A + B, 50 + 100)
Cumulative Weight after Endpoint C: 150 (the weight of A + B + C, 50+100+150)
Cumulative Weight after Endpoint D: 300 (the weight of A + B + C +D, 50+100+150+300)
Cumulative Weight after Endpoint E: 600 (the weight of A + B + C + D +E, 150+100+150+300+500)
Weight Distribution Percentage Calcuation:
Route A 50/1200×100%=4.17%
Route B 100/1200×100%=8.33%
Route C 150/1200×100%=12.50%
Route D 300/1200×100%=25.00%
Route E 600/1200×100%=50.00%
Step 4: Select the Endpoint Route Based on Random Weight
The randomWeight determines which Endpoint route is selected:
If
randomWeightis between 1 and 50, Endpoint A is selected (4.17% chance)If
randomWeightis between 51 and 100, Endpoint B is selected(8.33% chance)If
randomWeightis between 100 and 150, Endpoint C is selected(12.50% chance)If
randomWeightis between 150 and 300, Endpoint D is selected(25 % chance)If
randomWeightis between 300 and 600, Endpoint E is selected(50% chance)
OPAI TPM Exhausted Scenario:

In this image, An first endpoint is throttled with HTTP response code 429 & APIM is routing request to other available backend based on weight
When OpenAI endpoint starts getting traffic beyond its token capacity limit, it throws an HTTP Status code "429" which translate to that is 'server is busy'
In that situation APIM is configured with health probe of endpoint based on '429' using Retry-After logic
Once APIM gets HTTP 429 from its endpoint , it starts to priortize other endpoint in weightage order and forward most request next highest weight assigned endpoint
Meanwhile it continue to retry health probe request to actuall thortlled endpoint after waiting for 60 second
OpenAI PTU Tier (Provision throughput Unit ):
To Ensure OpenAI endpoint with PTU plan should be always be preferred. you would need adjust PTU instance endpoint in such way that it out weight other endpoint significantly, effectively making it the most likely choice under normal circumstances.
1. Significantly Increase PTU endpoint Weight: Increase the weight of PTU endpoint so high compared to Endpoint E,D,C that the random selection virtually always lands on PTU based OpenAI endpoint.In Above example highest weight was 600 for Endpoint E, we could set PTU endpoint Weight something like 5000 or even more.This would make PTU endpoint overwhelmingly more likely to be selected.
2.Preferential Selection: Modify the selection logic to check for PTU endpoint availability first and choose it by default, only falling back to other endpoint A/B/C under certain conditions (e.g., Route C is down or throttling). This requires a bit of custom logic in your policy.
3.Use Priority Method: If your system allows, Clubbed a Prority based system where routes are tried in order of priority rather than by weight. PTU would be given the highest priority, with endpoint A,B,C & D as fallbacks.
Setup Policy in APIM:
Create APIM instance with desired SKU if not exist already & enable managed identity on APIM
Make sure to have same model(GPT35/4) & deployment name across all OpenAI endpoint
Grant following Az RBAC "Cognitive OpenAI User" on All OpenAI resources via 'Access Control(IAM)' blade to APIM managed identity
Download Az OpenAI API version Schema and inetrgrate with APIM using Import, you could read more on OpenAI Integration instruction here
Once OpenAI API is imported, copy and paste this policy into APIM editor
Modify or Replace from line no #15-43 with your existing All OpenAI instance endpoint details
Assigned weight to each endpoint listed under routes as per its TPM Limits.
Update your OpenAI model deployment name and routes index array sequence at line no #47,48 also at line no #129
Perform Test run with APIM traces enabled to see policy logic in action
<policies>
<inbound>
<base />
<!-- Getting OpenAI clusters configuration -->
<authentication-managed-identity resource="https://cognitiveservices.azure.com" />
<cache-lookup-value key="@("oaClusters" + context.Deployment.Region + context.Api.Revision)" variable-name="oaClusters" />
<!-- If we can't find the configuration, it will be loaded -->
<choose>
<when condition="@(context.Variables.ContainsKey("oaClusters") == true)">
<set-variable name="oaClusters" value="@{
JArray routes = new JArray();
JArray clusters = new JArray();
if(context.Deployment.Region == "West Europe" || true)
{
routes.Add(new JObject()
{
{ "name", "openai 1" },
{ "location", "eastus" },
{ "url", "https://openaiendpoint-a.openai.azure.com/" },
{ "isThrottling", false },
{ "weight", "100"},
{ "retryAfter", DateTime.MinValue }
});
routes.Add(new JObject()
{
{ "name", "openai 2" },
{ "location", "UK SOuth" },
{ "url", "https://openaiendpoint-b.openai.azure.com/" },
{ "isThrottling", false },
{ "weight", "150"},
{ "retryAfter", DateTime.MinValue }
});
routes.Add(new JObject()
{
{ "name", "openai 3" },
{ "location", "Central india" },
{ "url", "https://openendpointai-c.openai.azure.com/" },
{ "isThrottling", false },
{ "weight", "300"},
{ "retryAfter", DateTime.MinValue }
});
clusters.Add(new JObject()
{
{ "deploymentName", "gpt35turbo16k" },
{ "routes", new JArray(routes[0], routes[1], routes[2]) }
});
}
else
{
//Error has no clusters for the region
}
return clusters;
}" />
<!-- Add cluster configurations to cache -->
<cache-store-value key="@("oaClusters" + context.Deployment.Region + context.Api.Revision)" value="@((JArray)context.Variables["oaClusters"])" duration="86400" />
</when>
</choose>
<!-- Getting OpenAI routes configuration based on deployment name, region and api revision -->
<cache-lookup-value key="@(context.Request.MatchedParameters["deployment-id"] + "Routes" + context.Deployment.Region + context.Api.Revision)" variable-name="routes" />
<!-- If we can't find the configuration, it will be loaded -->
<choose>
<when condition="@(context.Variables.ContainsKey("routes") == true)">
<set-variable name="routes" value="@{
string deploymentName = context.Request.MatchedParameters["deployment-id"];
JArray clusters = (JArray)context.Variables["oaClusters"];
JObject cluster = (JObject)clusters.FirstOrDefault(o => o["deploymentName"]?.Value<string>() == deploymentName);
if(cluster == null)
{
//Error has no cluster matched the deployment name
}
JArray routes = (JArray)cluster["routes"];
return routes;
}" />
<!-- Set total weights for selected routes based on model -->
<set-variable name="totalWeight" value="@{
int totalWeight = 0;
JArray routes = (JArray)context.Variables["routes"];
foreach (JObject route in routes)
{
totalWeight += int.Parse(route["weight"].ToString());
}
return totalWeight;
}" />
<!-- Set cumulative weights for selected routes based on model-->
<set-variable name="cumulativeWeights" value="@{
JArray cumulativeWeights = new JArray();
int totalWeight = 0;
JArray routes = (JArray)context.Variables["routes"];
foreach (JObject route in routes)
{
totalWeight += int.Parse(route["weight"].ToString());
cumulativeWeights.Add(totalWeight);
}
return cumulativeWeights;
}" />
<!-- Add cluster configurations to cache -->
<cache-store-value key="@(context.Request.MatchedParameters["deployment-id"] + "Routes" + context.Deployment.Region + context.Api.Revision)" value="@((JArray)context.Variables["routes"])" duration="86400" />
</when>
</choose>
<set-variable name="routeIndex" value="-1" />
<set-variable name="remainingRoutes" value="1" />
</inbound>
<backend>
<retry condition="@(context.Response != null && (context.Response.StatusCode == 429 || context.Response.StatusCode >= 500) && ((Int32)context.Variables["remainingRoutes"]) > 0)" count="3" interval="0">
<set-variable name="routeIndex" value="@{
Random random = new Random();
int totalWeight = (Int32)context.Variables["totalWeight"];
JArray cumulativeWeights = (JArray)context.Variables["cumulativeWeights"];
int randomWeight = random.Next(1, totalWeight + 1);
int nextRouteIndex = 0;
for (int i = 0; i < cumulativeWeights.Count; i++)
{
if (randomWeight <= cumulativeWeights[i].Value<int>())
{
nextRouteIndex = i;
break;
}
}
return nextRouteIndex;
}" />
<!-- This is the main logic to pick the route to be used -->
<set-variable name="routeUrl" value="@(((JObject)((JArray)context.Variables["routes"])[(Int32)context.Variables["routeIndex"]]).Value<string>("url") + "/openai")" />
<set-variable name="routeLocation" value="@(((JObject)((JArray)context.Variables["routes"])[(Int32)context.Variables["routeIndex"]]).Value<string>("location"))" />
<set-variable name="routeName" value="@(((JObject)((JArray)context.Variables["routes"])[(Int32)context.Variables["routeIndex"]]).Value<string>("name"))" />
<set-variable name="deploymentName" value="@("gpt35turbo16k")" />
<set-backend-service base-url="@((string)context.Variables["routeUrl"])" />
<forward-request buffer-request-body="true" />
</retry>
</backend>
<outbound>
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>
Policy Internals:
This policy incorporates several key configuration items that enable it to efficiently manage and route API requests to OpenAI ChatGPT instances. so Highlighting few of configurations can provide valuable insights to blog readers
<authentication-managed-identity resource="https://cognitiveservices.azure.com" />
<cache-lookup-value key="@("oaClusters" + context.Deployment.Region + context.Api.Revision)" variable-name="oaClusters" />
For authentication managed identity is used in this case instead of keys, so first line enable policy to leverage manage identity.
In next block Attempts to fetch pre-configured OpenAI cluster information from the cache, significantly reducing the overhead of reconstructing the configuration for each API call.
<choose>
<when condition="@(context.Variables.ContainsKey("oaClusters") == true)">
<set-variable name="oaClusters" value="@{
JArray routes = new JArray();
JArray clusters = new JArray();
if(context.Deployment.Region == "West Europe" || true)
{
routes.Add(new JObject()
{
{ "name", "openai-a" },
{ "location", "india" },
{ "url", "https://openai-endpoint-a.openai.azure.com/" },
{ "isThrottling", false },
{ "weight", "600"},
{ "retryAfter", DateTime.MinValue }
});
clusters.Add(new JObject()
{
{ "deploymentName", "gpt35turbo16k" },
{ "routes", new JArray(routes[0], routes[1], routes[2]) }
});
}
else
{
//Error has no clusters for the region
}
return clusters;
In choose block complex logic dynamically generates the configuration for OpenAI clusters if not found in the cache.
Depending on the deployment region, the policy constructs clusters with specific attributes (e.g., name, location, URL, weight) reflecting each OpenAI instance's characteristics and intended traffic handling capacity.
Each route is assigned a specific weight, dictating its selection probability for handling incoming requests, thereby facilitating a balanced and efficient distribution of traffic based on the defined capacities or priorities.
Defines the OpenAI model (in this case,
gpt35turbo16k) to which API requests should be routed. This specification allows the policy to support different OpenAI models,By clearly defining thedeploymentName.
<choose>
<when condition="@(context.Variables.ContainsKey("routes") == true)">
<set-variable name="routes" value="@{
string deploymentName = context.Request.MatchedParameters["deployment-id"];
JArray clusters = (JArray)context.Variables["oaClusters"];
JObject cluster = (JObject)clusters.FirstOrDefault(o => o["deploymentName"]?.Value<string>() == deploymentName);
if(cluster == null)
{
//Error has no cluster matched the deployment name
}
JArray routes = (JArray)cluster["routes"];
return routes;
}" />
- In this block it checks if the
routesconfiguration for the current API request's deployment (e.g., a specific OpenAI model indicated bydeployment-id) is already available within the context variables. If so, it proceeds to confirm and utilize these endpoint routes for further processing.
<!-- Set total weights for selected routes based on model -->
<set-variable name="totalWeight" value="@{
int totalWeight = 0;
JArray routes = (JArray)context.Variables["routes"];
foreach (JObject route in routes)
{
totalWeight += int.Parse(route["weight"].ToString());
}
return totalWeight;
}" />
<!-- Set cumulative weights for selected routes based on model-->
<set-variable name="cumulativeWeights" value="@{
JArray cumulativeWeights = new JArray();
int totalWeight = 0;
JArray routes = (JArray)context.Variables["routes"];
foreach (JObject route in routes)
{
totalWeight += int.Parse(route["weight"].ToString());
cumulativeWeights.Add(totalWeight);
}
return cumulativeWeights;
}" />
Both of these variable are key elements in functioning of this policy
Totalweight: by iterating over each route in the endpoint routes collection and summing up their weights, it represents the aggregate capacity of all endpoint routes. This total is crucial because it defines the range within which a random number can be generated to select a route proportionally based on its weight.
Cumulative weight:As the policy iterates through endpoint routes, it progressively adds each route's weight to a running total, creating a series of increasing values. This cumulative approach allows for determining which route to select by generating a random number within the totalweight range and finding the segment (route) where this number falls.
<retry condition="@(context.Response != null && (context.Response.StatusCode == 429 || context.Response.StatusCode >= 500) && ((Int32)context.Variables["remainingRoutes"]) > 0)" count="3" interval="30">
<set-variable name="routeIndex" value="@{
Random random = new Random();
int totalWeight = (Int32)context.Variables["totalWeight"];
JArray cumulativeWeights = (JArray)context.Variables["cumulativeWeights"];
int randomWeight = random.Next(1, totalWeight + 1);
int nextRouteIndex = 0;
for (int i = 0; i < cumulativeWeights.Count; i++)
{
if (randomWeight <= cumulativeWeights[i].Value<int>())
{
nextRouteIndex = i;
break;
}
}
return nextRouteIndex;
}" />
Retrypolicy segment is mentioned within backend block is a mechanism designed to handle scenarios where an OpenAI ChatGPT instance—fails due to throttling (HTTP 429) or server errors (HTTP status codes >= 500). This segment also takes into account the availability of alternative endpoint routes for retrying the request.The maximum number of retry attempts is set to 3, meaning the policy will try up to three times to forward the request to a backend service before marking as unhealthy.Also retry attempts will be made on interval of 30 second one after another
Random number is generated within the range of 1 to the
totalWeightof all available endpoint routes. This random weight determines which route will be selected for the next retry attempt.it terates through the cumulative weights of all endpoint routes stored incumulativeWeightsvariableWhile index of the selected route (
nextRouteIndex) is determined and stored, guiding the API management platform on which route to use for the next retry attempt.By incorporating a retry mechanism with weighted random route selection, it ensures that requests are not simply retried on the same route that might be experiencing issues but are intelligently rerouted based on predefined weights reflecting each route's capacity
system effectively balances the load across multiple routes, minimizing the impact of temporary issues on one or more endpoint
Appendix
For simple easy to deploy load balance options on AppGW/AFD refer my this repo
On overall reference Archiecture pattern of APIM & OpenAI can refer this doc